
github -borisdayma/dalle -mini:dall・e mini-テキストプロンプトから画像を生成します。?
0ダレミニはどのように機能しますか
何も起こらない場合は、githubデスクトップをダウンロードして再試行してください.
保存された検索を使用して、結果をより迅速にフィルタリングします
キャンセル保存された検索を作成します
. セッションを更新するためにリロードします. 別のタブまたはウィンドウでサインアウトしました. セッションを更新するためにリロードします. 別のタブまたはウィンドウにアカウントを切り替えました. セッションを更新するためにリロードします.
dall・E mini-テキストプロンプトから画像を生成する
ライセンス
Borisdayma/dalle-mini
このコミットは、このリポジトリのどのブランチにも属しておらず、リポジトリの外側のフォークに属している可能性があります.
提供されたブランチ名にタグが既に存在します. 多くのgitコマンドはタグ名とブランチ名の両方を受け入れているため、このブランチを作成すると、予期しない動作が発生する可能性があります. このブランチを作成したいですか??
- 地元
- コードスペース
.
. CLIの詳細をご覧ください.
必要なサインイン
コードスペースを使用するためにサインインしてください.
Githubデスクトップの起動
.
何も起こらない場合は、githubデスクトップをダウンロードして再試行してください.
Xcodeの起動
.
Visual Studioコードの起動
準備ができたら、コードスペースが開きます.
コードスペースの準備に問題がありました、もう一度やり直してください.
最新のコミット
git統計
最新のコミット情報をロードできませんでした.
最新のコミットメッセージ
2022年10月23日17:35
2021年11月30日04:38
2021年11月30日04:14
readme.MD
Dall・E Mini
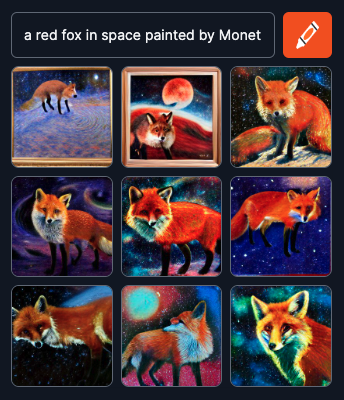
?
それはどのように機能しますか?
レポートを参照してください。
- dall・E mini-任意のテキストから画像を生成する
- Dall・E Mini-説明
依存関係のインストール
.
開発のために、リポジトリをクローンしてPIPインストール-eを使用します “.[dev] ” . PRを作成する前に、メイクスタイルでスタイルをチェックしてください .
パイプラインを段階的に実験することができます。パイプラインノートブック
Dall・E Miniのトレーニング
.
よくある質問
最新のモデルを見つける場所?
訓練されたモデルは��モデルハブにあります:
- 画像をエンコード/デコードするためのVQGAN-F16-16384
?
「アボカドの形のアームチェア」は、モデルの機能を説明するためにDall・EをリリースするときにOpenaiによって使用されました. このプロンプトで予測を成功させることは、私たちにとって大きなマイルストーンを表しています.
. 報告の問題から修正/改善の提案、またはクールなプロンプトでモデルのテストまで、あらゆる貢献が歓迎されます!
- Dall-E Playground Repositoryを使用して自分のアプリをスピンオフします(Saharに感謝)
- ループ中のワークフローで生成、拡散、アップスケーリングのためにdall・eフロープロジェクトをお試しください(Han Xiaoに感謝します)
- 複製、ブラウザ、またはAPI経由で実行します
謝辞
- flax/jaxコミュニティウィークを整理するための顔を抱き締める
- コンピューティングリソースを提供するためのGoogleTPU Research Cloud(TRC)プログラム
- 実験追跡とモデル管理のためのインフラストラクチャを提供するためのウェイトとバイアス
著者と貢献者
Dall・E Miniは最初に次のように開発されました。
- クールなアイデアをテストして交換するためのDalle-PytorchとEleutheraiのコミュニティ
- 分散型シャンプーオプティマイザーを追加し、常に素晴らしい提案をしてくれたRohan Anil
- Phil Wangはトランスバリアントの多くのクールな実装を提供し、X-Transformersと興味深い洞察を提供しています
- スーパーコンディショニングのためのキャサリンクローソン
- グラデーションチームは私たちのアプリのために素晴らしいUIを作りました
dall・eミニがあなたの研究に役立つか、参照したいと思う場合は、次のbibtexエントリを使用してください.
@misc、doi =、month =、title =、url =、year => 参照
- 「gluバリアントは変圧器を改善します」
- 「Normformer:追加の正規化による変圧器事前化の改善」
- 「Swin Transformer:シフトウィンドウを使用した階層ビジョントランス」
- 「Cogview:トランスフォーマー経由のテキストから画像の生成の習得」
- 「ルート平均平方層層の正規化」
- 「シンクフォーマー:二重に確率的な注意を払ったトランス
- 「基礎変圧器
引用
< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > < title=, author=, year=, url= > < title=, author=, year=, eprint= archivePrefix=, primaryClass= > @misc< title=, author=, year=, eprint=, archivePrefix=, primaryClass= > @inproceedings< title=, author=, booktitle=, year= > < title = , author = , year = , eprint = , archivePrefix = , primaryClass = > @misc< title = , author = , year = , eprint = , archivePrefix = , primaryClass = > @misc< title = , url = , author = , publisher = , year = , > @misc< title = , url = , author = , publisher = , year = , > @misc< title = , url = , author = , publisher = , year = , > について
dall・E mini-テキストプロンプトから画像を生成する
ダレミニはどのように機能しますか?
. これがどのように機能しますか.
ルイ・ブシャール

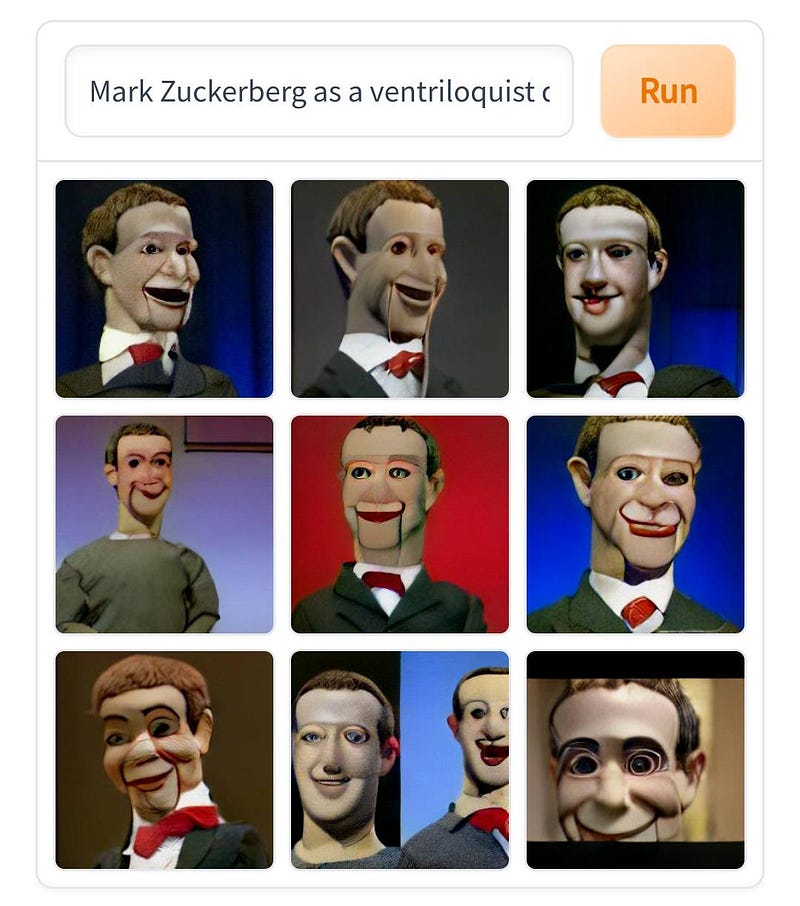
過去数日間にTwitterフィードのような写真を見たことがあると思います. あなたがそれらが何であるか疑問に思った場合、それらはDall・E Miniと呼ばれるAIによって生成された画像です. あなたがそれらを見たことがないなら、あなたは見逃しているのでこの記事を読む必要があります. これがどのように可能か疑問に思うなら、あなたは完璧な記事に載っていて、5分以内に答えを知るでしょう.
この名前、Dall・Eは、このモデルの2つのバージョンを過去1年間に作成したこのモデルの2つのバージョンを信じられないほど鳴らしているので、すでにベルを鳴らしなければなりません。. しかし、これは異なります. Dall・E Miniは、Dall・Eの最初のバージョンに触発されたオープンソースコミュニティが作成したプロジェクトであり、それ以来進化し続けています。.
はい、これはあなたがハギングフェイスのおかげですぐにそれで遊ぶことができることを意味します.
リンクは以下の参考文献にありますが、この記事をプレイする前にさらに数秒前に挙げてください. それはそれだけの価値があり、あなたはあなたがあなたの周りに知っている誰よりもこのAIについてもっと多くを知っているでしょう.

コアでは、Dall・E MiniはDall・Eに非常に似ているので、モデルに関する私の最初のビデオはこれの素晴らしい紹介です. .
まず、テキストプロンプトを理解し、それに続く画像を生成する必要があります。2つの非常に異なるモデルを必要とする2つの非常に異なるもの. Dall・Eの主な違いは、モデルのアーキテクチャとトレーニングデータにありますが、エンドツーエンドのプロセスはほとんど同じです. ここには、BARTと呼ばれる言語モデルがあります. BARTは、テキスト入力を次のモデルで理解できる言語に変換するように訓練されたモデルです. . BARTはテキストのキャプションを取り、それを離散トークンに変換し、生成された画像と入力として送信された画像の違いに基づいて調整します.
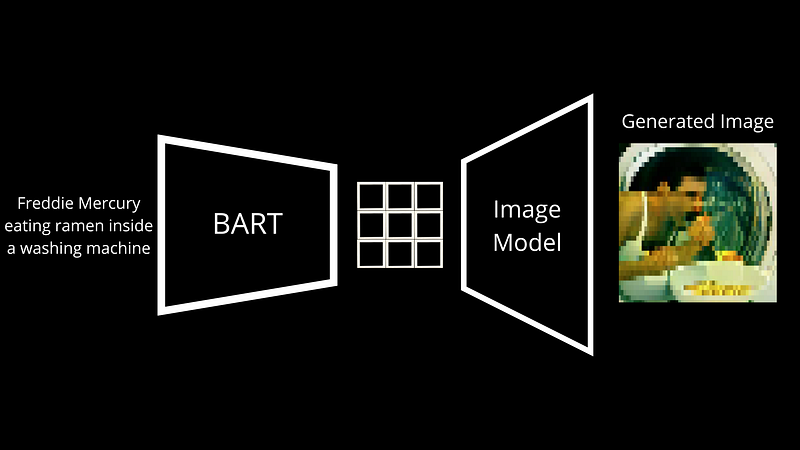
しかし、その後、イメージを生成するこのことは何ですか? これをデコーダーと呼びます. BARTによって作成されたこの新しいキャプション表現がエンコードと呼ばれ、画像にデコードします. .
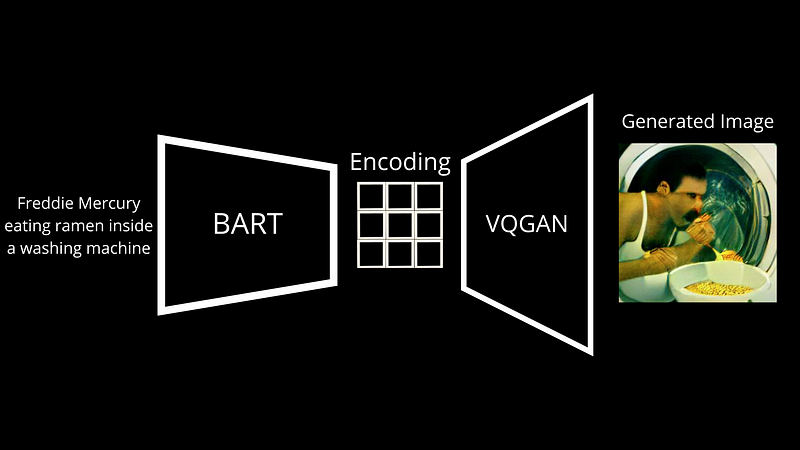
要するに、VQGANは反対のことをするのに最適なアーキテクチャです. そのようなエンコードマッピングから移動し、それから画像を生成する方法を学びます. . ここでは同じことですが、文を形成する文字の代わりに画像を形成するピクセルで. インターネットから何百万ものエンコーディングイメージのペアを通じて学習するため、基本的にはキャプション付きの公開された画像があり、初期画像の再構築においてかなり正確になります。.
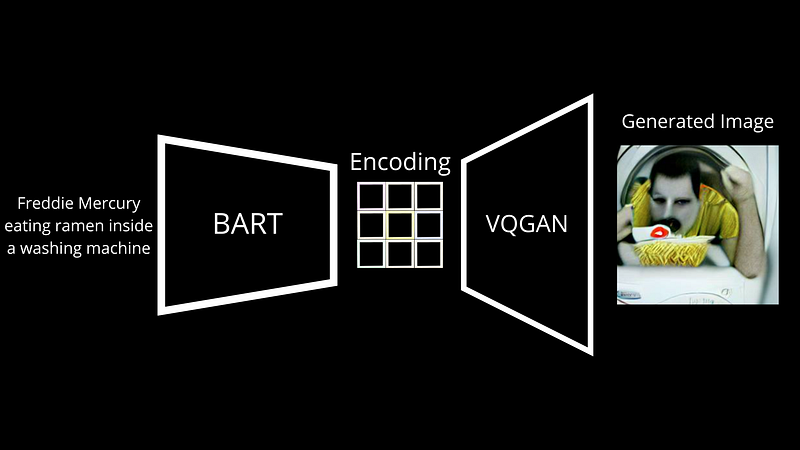
次に、トレーニング中のもののように見えるが少し異なる新しいエンコーディングを与えることができ、まったく新しいが類似した画像が生成されます. 同様に、通常、これらのエンコーディングに少しのノイズを追加して、同じテキストプロンプトを表す新しい画像を生成します.
そしてボイラ! これがDall・E Miniがテキストキャプションから画像を生成する方法を学ぶ方法です.
ビデオでその他の結果を見る:
私が述べたように、それはオープンソースであり、あなたはハギングフェイスのおかげですぐにそれをプレイすることさえできます. もちろん、これは単なる簡単な概要であり、明確にするためのいくつかの重要な手順を省略しました. . また、最近、同じテキストプロンプトのDall・E 2との比較結果と同様に、いくつかの面白い結果を紹介しているYouTubeで2つの短いビデオを公開しました.
!
この記事とビデオを楽しんだことを願っています。もしそうなら、コメントで私に知らせて、同じように残してください。.
来週ではなく、2週間で別の素晴らしい論文でお会いしましょう!
►https:// discord.gg/learaitogether
.

!
微調整によるAIパフォーマンスを後押しします
ルイ・ブシャール2023年9月19日•6分読む

MVDREAM:新しいテキストから3Dへのアプローチ(説明)!
ルイ・ブシャール2023年9月10日•6分読む

AIディープラーニングが説明されました
Dall-E 2は、テクノロジーの固有の約束を追求するOpenaiの画期的な研究です。. ほとんどの人は、描くスキルや才能がありません. お金を持っていない人は専門家を雇うことができます. Dall-E 2の魅力は、スキルや収入に関係なく、プロのアーティストの表現力のある能力を持って、各人を武装させています.
hotpot.AIは、消費者がAIイメージジェネレーターのパワーを探索し、活用する簡単な方法を提供します.
ダレミニ
.
AIで自分自身を再考してください. さまざまなスタイルやシーンで自分自身のAIセルフィー、AIのヘッドショット、企業写真、魅力的なショットを作成する. ソーシャルメディアプロファイル、出会い系アプリ、LinkedInプロファイル、または単に新しい方法で自分自身を見るのに最適です.
ai art
人工知能の進歩により、誰もが人間の芸術家に指示するのと同じように、簡単な指示でアートを作成することができます. この技術により、数十億が以前は不可能な方法で視覚的に自分自身を表現することが可能になります.
Nvidia、Google、安定性の先駆的な研究に基づく.AI、およびOpenai、これらのAI画像モデルは、簡単な指示を理解し、画像を作成できます。. しかし、この芸術か知性です?
簡単な答え:これらの製品がアートやインテリジェンスを反映しているかどうかは関係ありません. 重要なのは、彼らが人々を助けるかどうかです. ?
AI Artの詳細を読んでください.